背景
以深度学习为代表的人工智能模型在诸多任务上取得了优异的性能,但是其在对抗样本攻击下的鲁棒性存在严重不足。为了提升深度学习模型的鲁棒性,对抗训练通过采用对抗样本作为一种数据增强方式,成为目前最为主流的防御方式。
然而,对抗训练算法仍存在很多问题,包括鲁棒泛化误差较大、鲁棒过拟合(robust overfitting)等。目前,仍然缺乏对深度学习对抗训练的机理的深入理解与分析。本文从对抗训练的记忆现象(memorization effect)角度分析对抗训练中存在的收敛性、泛化性、过拟合等问题,试图进一步理解并提升对抗训练。
对抗训练的记忆现象
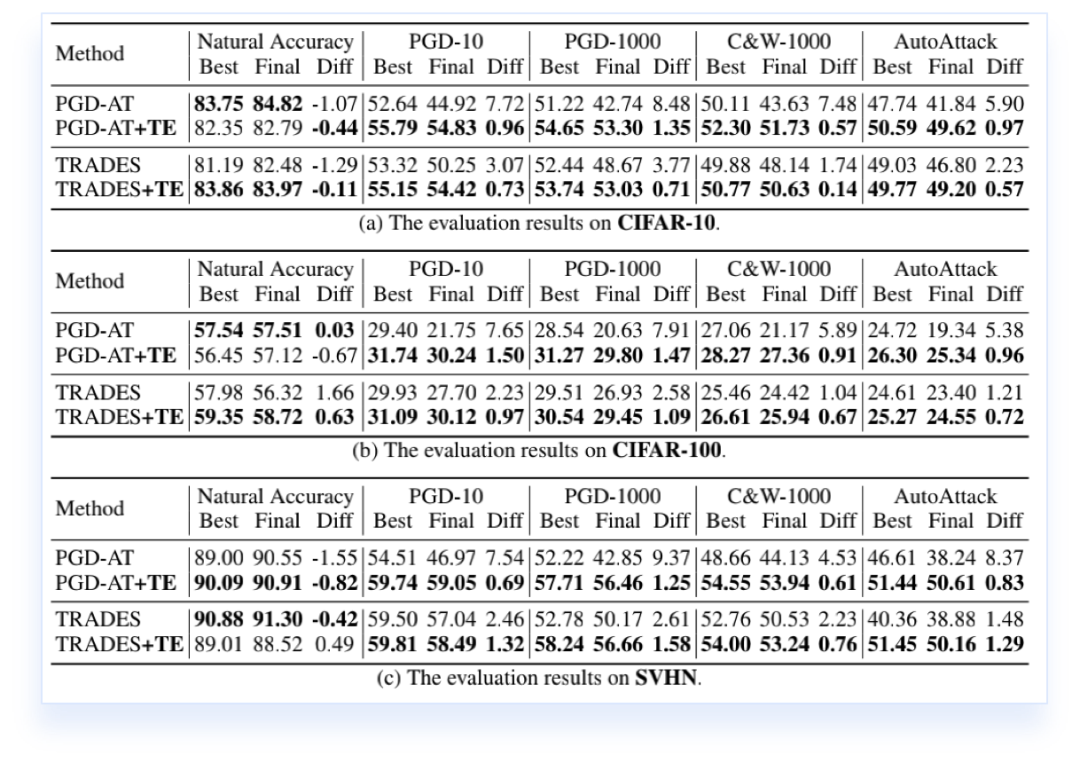
为了探究对抗训练的记忆现象,本文采用经典的实验方法,即采用随机标签的数据集进行对抗训练。选取PGD-AT [1]和TRADES [2]两种最为典型的对抗训练算法,在CIFAR-10数据集上采用随机标签进行对抗训练。模型的训练准确率如下图所示:
从图中可以看到,PGD-AT在随机标签的情况下无法收敛,而TRADES可以达到100%的训练准确率。以上实验证实了深度学习模型有足够的容量记忆训练集所有的对抗样本,但是并不是所有的方法都能够收敛。
收敛性分析
为了进一步解释PGD-AT在随机标签情况下的实验现象,本文进一步探索对抗训练的收敛性。首先,通过理论分析,本文得出以下结论:
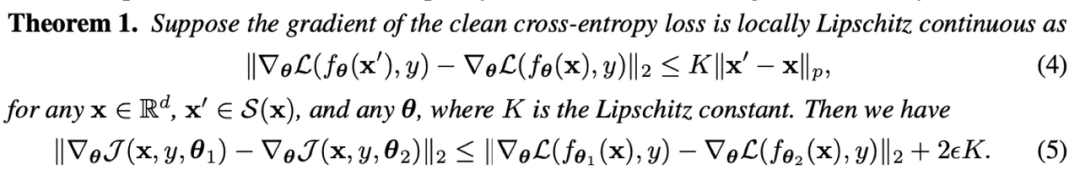
即PGD-AT的梯度存在不平稳的现象,其相比于正常训练的梯度会有较大的变化。通过进一步实验,可以得到模型在权重发生微小变化情况下的梯度的变化曲线:

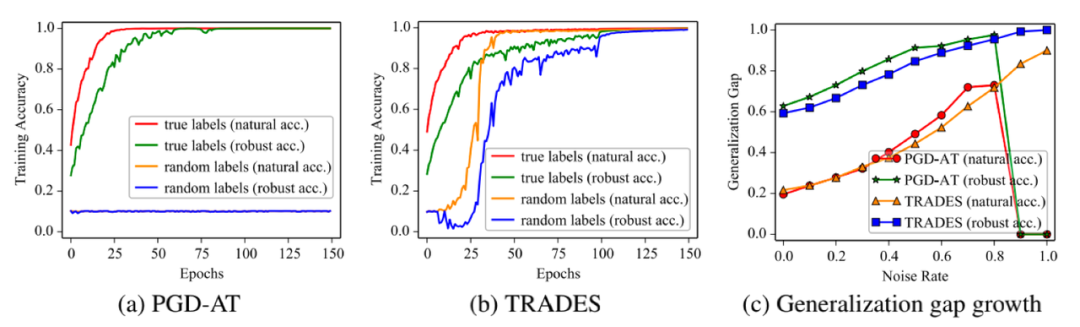
从上图(a)中可以看到,模型权重发生很小变化的情况下,PGD-AT的梯度有非常大的改变,而TRADES的梯度是较为平稳的,这也进一步说明对抗训练存在梯度不平滑的现象。因此,在极端情况下,PGD-AT无法收敛。
鲁棒过拟合分析
本文通过实验,发现深度学习模型可以记忆训练集所有的对抗样本,这就导致了模型很容易出现鲁棒过拟合的现象。为了解决这一问题,本文提出了采用时序集成(temporal ensembling)的方式解决对抗训练中使用one-hot标签可能存在的噪声的问题。通过以上方法,可以有效缓解对抗训练中的过拟合问题,得到鲁棒性更好的深度学习模型。实验结果如下图、表所示。